


Một mô hình trí tuệ nhân tạo (AI) mới vừa đạt được kết quả ngang tầm con người trong bài kiểm tra được thiết kế để đo lường “trí thông minh tổng quát”.
Vào ngày 20 tháng 12, hệ thống o3 của OpenAI đạt 85% điểm chuẩn ARC-AGI, cao hơn nhiều so với điểm tốt nhất của AI trước đó là 55% và ngang bằng với điểm trung bình của con người. Nó cũng đạt điểm cao trong một bài kiểm tra toán rất khó.
Tạo ra trí tuệ nhân tạo tổng quát, hay AGI, là mục tiêu đã nêu của tất cả các phòng thí nghiệm nghiên cứu AI lớn. Thoạt nhìn, OpenAI dường như ít nhất đã đạt được một bước quan trọng hướng tới mục tiêu này.
Trong khi sự hoài nghi vẫn còn, nhiều nhà nghiên cứu và phát triển AI cảm thấy có điều gì đó vừa thay đổi. Đối với nhiều người, viễn cảnh AGI giờ đây dường như thực tế hơn, cấp bách hơn và gần gũi hơn dự đoán. Họ có đúng không?
Khái quát hóa và trí tuệ
Để hiểu kết quả o3 có ý nghĩa gì, bạn cần hiểu nội dung của bài kiểm tra ARC-AGI. Về mặt kỹ thuật, đây là bài kiểm tra “hiệu quả lấy mẫu” của hệ thống AI trong việc thích ứng với điều gì đó mới – hệ thống cần xem bao nhiêu ví dụ về một tình huống mới để tìm ra cách hoạt động.
Một hệ thống AI như ChatGPT (GPT-4) không hiệu quả lắm về mẫu. Nó đã được “huấn luyện” trên hàng triệu ví dụ về văn bản của con người, xây dựng các “quy tắc” xác suất về những tổ hợp từ nào có khả năng xảy ra nhất.
Kết quả là khá tốt ở các tác vụ thông thường. Nó kém ở những nhiệm vụ không phổ biến vì nó có ít dữ liệu hơn (ít mẫu hơn) về những nhiệm vụ đó.
Cho đến khi các hệ thống AI có thể học hỏi từ một số lượng nhỏ ví dụ và thích ứng với hiệu quả mẫu cao hơn, chúng sẽ chỉ được sử dụng cho những công việc lặp đi lặp lại và những công việc mà đôi khi có thể chấp nhận được lỗi.
Khả năng giải quyết chính xác các vấn đề mới hoặc chưa biết trước đây từ các mẫu dữ liệu hạn chế được gọi là khả năng khái quát hóa. Nó được coi là một yếu tố cần thiết, thậm chí cơ bản của trí thông minh.
Lưới và mẫu
Điểm chuẩn ARC-AGI kiểm tra khả năng thích ứng hiệu quả của mẫu bằng cách sử dụng các bài toán lưới vuông nhỏ như bài toán dưới đây. AI cần tìm ra mô hình biến lưới bên trái thành lưới bên phải.
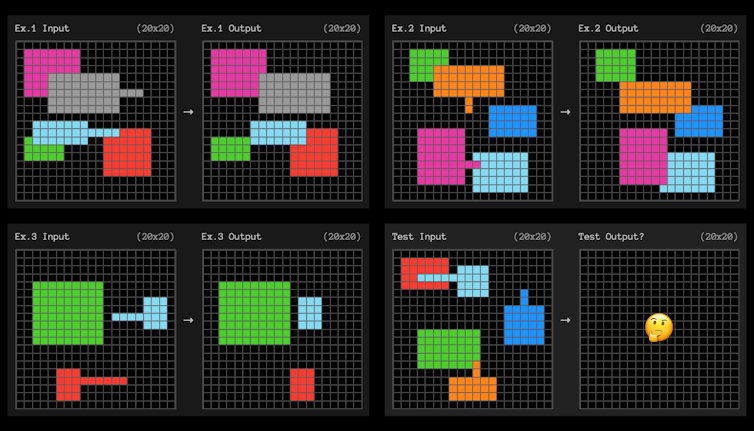
Giải thưởng ARC
Mỗi câu hỏi đưa ra ba ví dụ để học hỏi. Sau đó, hệ thống AI cần tìm ra các quy tắc “tổng quát hóa” từ ba ví dụ đến ví dụ thứ tư.
Những bài kiểm tra này rất giống với các bài kiểm tra IQ mà đôi khi bạn có thể nhớ được ở trường.
Quy tắc yếu và khả năng thích ứng
Chúng tôi không biết chính xác OpenAI đã thực hiện điều đó như thế nào, nhưng kết quả cho thấy mô hình o3 có khả năng thích ứng cao. Chỉ từ một vài ví dụ, nó tìm thấy các quy tắc có thể được khái quát hóa.
Để tìm ra một khuôn mẫu, chúng ta không nên đưa ra bất kỳ giả định không cần thiết nào hoặc đưa ra những giả định cụ thể hơn mức cần thiết. Về lý thuyết, nếu bạn có thể xác định được những quy tắc “yếu nhất” làm được điều mình muốn thì bạn đã phát huy tối đa khả năng thích ứng với các tình huống mới.
Chúng ta có ý gì khi nói đến những quy tắc yếu nhất? Định nghĩa kỹ thuật rất phức tạp, nhưng các quy tắc yếu hơn thường là những quy tắc có thể được mô tả bằng các câu lệnh đơn giản hơn.
Trong ví dụ trên, cách diễn đạt quy tắc bằng tiếng Anh đơn giản có thể giống như sau: “Bất kỳ hình dạng nào có đường nhô ra sẽ di chuyển đến cuối dòng đó và 'che đi' bất kỳ hình dạng nào khác mà nó trùng lặp.”
Tìm kiếm chuỗi suy nghĩ?
Mặc dù chúng tôi vẫn chưa biết làm thế nào OpenAI đạt được kết quả này, nhưng có vẻ như họ không cố tình tối ưu hóa hệ thống o3 để tìm ra các quy tắc yếu. Tuy nhiên, để thành công trong các nhiệm vụ ARC-AGI, bạn phải tìm ra chúng.
Chúng tôi biết rằng OpenAI đã bắt đầu với phiên bản có mục đích chung của mô hình o3 (khác với hầu hết các mô hình khác vì nó có thể dành nhiều thời gian hơn để “suy nghĩ” về những câu hỏi khó) và sau đó huấn luyện nó đặc biệt cho bài kiểm tra ARC-AGI.
Nhà nghiên cứu AI người Pháp Francois Chollet, người thiết kế điểm chuẩn, tin rằng o3 tìm kiếm thông qua các “chuỗi suy nghĩ” khác nhau mô tả các bước để giải quyết nhiệm vụ. Sau đó nó sẽ chọn cái “tốt nhất” theo một số quy tắc được xác định lỏng lẻo, hay còn gọi là “heuristic”.
Điều này sẽ “không khác” với cách hệ thống AlphaGo của Google tìm kiếm thông qua các chuỗi nước đi khác nhau có thể có để đánh bại nhà vô địch cờ vây thế giới.
Bạn có thể coi những chuỗi suy nghĩ này giống như những chương trình phù hợp với các ví dụ. Tất nhiên, nếu nó giống như AI chơi cờ vây, thì nó cần một quy tắc tự nghiệm hoặc lỏng lẻo để quyết định chương trình nào là tốt nhất.
Có thể có hàng nghìn chương trình khác nhau dường như có giá trị như nhau được tạo ra. Heuristic đó có thể là “chọn cái yếu nhất” hoặc “chọn cái đơn giản nhất”.
Tuy nhiên, nếu nó giống như AlphaGo thì họ chỉ cần nhờ AI tạo ra phương pháp phỏng đoán. Đây là quá trình dành cho AlphaGo. Google đã đào tạo một mô hình để đánh giá các chuỗi động tác khác nhau là tốt hơn hoặc kém hơn các chuỗi khác.
Những gì chúng ta vẫn chưa biết
Câu hỏi đặt ra là liệu điều này có thực sự gần với AGI hơn không? Nếu đó là cách o3 hoạt động thì mô hình cơ bản có thể không tốt hơn nhiều so với các mô hình trước đó.
Các khái niệm mà mô hình học được từ ngôn ngữ có thể không còn phù hợp để khái quát hóa hơn trước nữa. Thay vào đó, chúng ta có thể chỉ nhìn thấy một “chuỗi suy nghĩ” có tính tổng quát hơn được tìm thấy thông qua các bước bổ sung trong quá trình đào tạo một chuyên gia về phương pháp phỏng đoán cho bài kiểm tra này. Bằng chứng, như mọi khi, sẽ nằm trong chiếc bánh pudding.
Hầu hết mọi thứ về o3 vẫn chưa được biết. OpenAI đã giới hạn tiết lộ ở một số bài thuyết trình trên phương tiện truyền thông và thử nghiệm sớm cho một số nhà nghiên cứu, phòng thí nghiệm và tổ chức an toàn AI.
Sự hiểu biết thực sự về tiềm năng của o3 sẽ đòi hỏi phải làm việc sâu rộng, bao gồm đánh giá, hiểu biết về sự phân bổ năng lực của nó, tần suất thất bại và tần suất thành công của nó.
Khi o3 cuối cùng được phát hành, chúng ta sẽ có ý tưởng tốt hơn nhiều về việc liệu nó có khả năng thích nghi gần như con người bình thường hay không.
Nếu vậy, nó có thể có tác động to lớn, mang tính cách mạng, kinh tế, mở ra một kỷ nguyên mới về trí thông minh tăng tốc tự cải thiện. Chúng tôi sẽ yêu cầu các tiêu chuẩn mới cho chính AGI và xem xét nghiêm túc về cách quản lý nó.
Nếu không thì đây vẫn sẽ là một kết quả ấn tượng. Tuy nhiên, cuộc sống hàng ngày sẽ vẫn như cũ.![]()
Michael Timothy Bennett, Nghiên cứu sinh, Trường Máy tính, Đại học Quốc gia Úc và Elija Perrier, Nghiên cứu viên, Trung tâm Công nghệ Lượng tử có Trách nhiệm Stanford, Đại học Stanford
Bài viết này được tái bản từ The Conversation theo giấy phép Creative Commons. Đọc bài viết gốc.